La donnée constitue aujourd’hui une richesse inestimable pour l’entreprise.
Dans une entreprise performante, les décisions doivent être prises sur la compréhension / l’analyse des données.
Si dans votre métier, ce n’est pas encore le cas, soyez certain que demain votre tour viendra.
Même s’il n’y a pas d’enjeux business actuels ou de point de douleur qui vous y oblige, s’engager dans cette voie permet rapidement des gains de productivité, de sécurité et de fiabilité immédiats.
Comme la transition ne se fait pas du jour au lendemain, autant s’y préparer dès maintenant.
La gestion de la donnée se fait au sein d’un système décisionnel, qui est une composante et au cœur du système d’information de l’entreprise.
Au travers de cet article, nous vous proposons de répondre à la question : comment faire de mon système décisionnel la pierre centrale de mon SI ?
En fonction des clients et de leur situation actuelle, il existe deux grandes catégories de chemin à emprunter qui mènent tous les deux au même résultat.
En partant d’un existant : il faut prendre en compte la continuité de la production des indicateurs existants, notion de temps / délai pour produire les nouveaux KPI, tiré parti des leçons de l’existant.
Passer directement à ce chapitre
En partant d’une feuille blanche : vous profitez des nouvelles technologies cloud pour une mise en place progressive, accessible à tout type d’entreprise.
Passer directement à ce chapitre
Avant de décrire comment y aller en fonction de votre point de départ, commençons par nous intéresser au système décisionnel cible, pierre centrale de votre Système d’Information .
A- DESCRIPTION DU SYSTÈME DÉCISIONNEL
Un système décisionnel est constitué de plusieurs « briques ». A chaque client/besoin, un sous-ensemble de briques est mis en place.
Ces briques sont modulaires et interagissent entre elles, le tout au sein d’un système décisionnel qui reste évolutif pour que l’architecture mise en place à un instant ‘T’ puisse évoluer en ajoutant de nouvelles briques sans remettre en cause l’existant. L’entrée de ce système, ce sont les données sources et la sortie est le reporting à destination des utilisateurs.
L’ensemble des traitements qui au sein de ce système décisionnel constitue la chaîne décisionnelle.
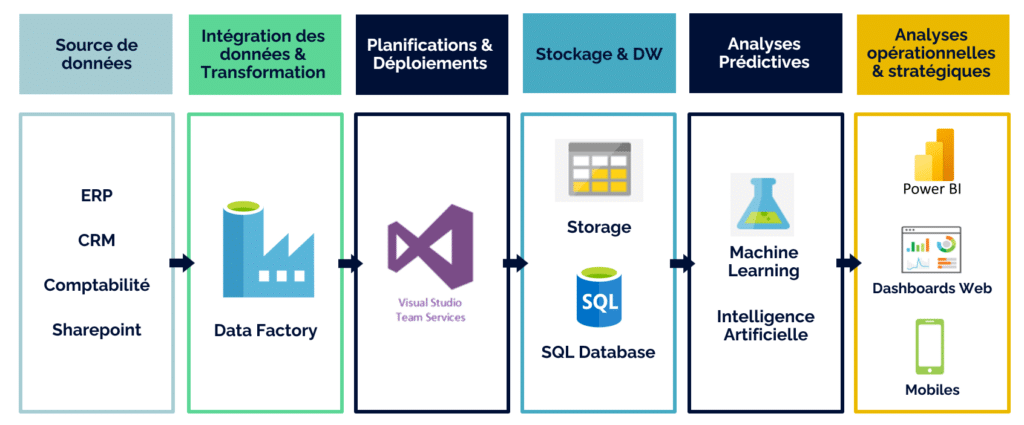
Les sources contiennent les données qui vont alimenter le système décisionnel. Elles sont issues du système d’information (CRM, ERP, Comptabilité, RH), de fichiers plats (xls, txt, …) ou encore de partenaires externes comme des prestataires ou des fournisseurs de données (INSEE, Panels, …).
Ces sources doivent être des sources réputées « récurrentes » pour permettre de rafraichir les données régulièrement. Des sources de données « éphémères » peuvent aussi être utilisées pour une analyse ponctuelle, mais elles ne sont pas forcément dans ce cas à intégrer au système décisionnel pour ne pas le polluer.
Les données pour une analyse ponctuelle pourront rentrer à un autre endroit de la chaîne en fonction des besoins de croisement avec les données décisionnelles (y compris juste au niveau du reporting permettant d’ajouter de nouvelles données externes).
Les sources doivent englober toutes les données de l’entreprise nécessaires à son pilotage.
Une des questions cruciales au niveau de ces sources est leur choix. En effet une donnée peut exister dans plusieurs systèmes (un client peut être dans un ERP et un CRM par exemple) et un premier travail est de bien les sélectionner : quelles sources pour quelle donnée, avec pour objectif tout au long de chaîne d’avoir des données propres pour sortir des analyses pertinentes.
Plus les sources ont-elles-mêmes les données pertinentes et propres, plus le travail en aval sera facilité.
Les sources, même les plus propres possibles doivent passer un certain nombre de contrôle pour garantir la qualité des données.
De façon macro, on peut les classer en 2 catégories :
- Les données de références plutôt liées à des axes d’analyses tels que les produits, catégories client, les calendriers, liste de valeurs, ….
Pour ces données il est possible de les stocker et les administrer dans un MDM référentiel qui permet de rechercher puis corriger les données qui n’ont pas de correspondance dans ce MDM pour les corriger (manuellement/automatiquement, à la source ou dans la chaîne décisionnelle).
Un exemple concret : sur une analyse de ventes par pays, un pays « Ittalie » doit sortir en erreur et être corrigé par « Italie » qui a une entrée MDM.
- Les cas à la marge sont traités via des moteurs de Data Cleansing qui permettre repérer les valeurs exceptionnelles (hors MDM) qui pourraient être incluses dans les données sources.
Un exemple concret : une commande avec un montant de 1Millard€ doit ressortir si l’ensemble des autres commandes sont entre 0 et 20k€ et un CA annuel de 200Millions€. Intégrer cette valeur fausserait complétement la restitution.
La qualité de ces données est cruciale car sinon les axes d’analyses seraient faussés et les restitutions illisibles voire aberrantes.
Les principaux types sont sous forme de Datalake, ODS ou encore de Staging.
En fonction du besoin il faudra utiliser l’un ou l’autre de ces composants intermédiaires.
- Le staging : c’est le stockage intermédiaire le plus simple car il est temporaire pour aider à préparer les données pour l’étape suivante de modélisation finale du DWH.
- L’ODS (Operational Data Store) : c’est une pré modélisation simple des données sources incluant une première dénormalisation des tables pour avoir des liens simples, au même niveau que les sources (pas d’agrégation), des données historisées si besoin (Slowly Changing Dimension). L’ODS permet au DWH d’être agnostique des sources de données car il doit contenir l’ensemble des données pour reconstituer si besoin le DWH.
Un ODS contient des données structurées
- Le Datalake : Cela peut s’apparenter à l’ODS mais en moins organisé car on y réplique généralement une partie des données sources sans « trop » les transformer. Il contient des données structurées mais aussi non structurées et est souvent associé à de forte volumétrie et un stockage rapide. On sauvegarde en masse les sources et on voit après ce dont on a besoin mais toutes les données sont disponibles.
Il y a principalement 2 types, le Datawarehouse (DWH) et le Datamart (DM) pour modéliser des KPI (mesures ou faits) classiques (agrégats) ou issus de calculs IA (statistiques / machine learning) pour être analysé selon des axes (dimensions).
Le DWH est l’ensemble de la base décisionnel alors que le(les) Datamart affiche(nt) un sous ensemble avec une vue fonctionnelle précise. Les données sont organisées souvent sous forme d’étoile ou flocon.
A titre d’exemple, un DWH peut contenir des domaines finances, production, RH, ventes, … sur l’ensemble de l’historique de l’entreprise alors qu’on pourra retrouver des DM avec un vision ventes sur un historique de 10 ans ou encore une vision finances sur les 5 dernières années.
Un DM pourrait aussi contenir certains indicateurs complexe intéressants pour certaines visions et peut être accessibles à des utilisateurs finaux pour faire leur propre requêtage.
Dans un projet, il y a forcément la mise en place du DWH, par contre la mise en place de DM est à voir en fonction de chaque besoin.
Le reporting est au bout de la chaine et c’est via ce biais que les données sont exposées aux utilisateurs et seront donc jugées. C’est une étape importante qui peut demander une conduite du changement adaptées. En effet, les utilisateurs ont des habitudes très ancrées (tableurs Excel, liste, propre reporting, …) et ce changement n’est pas à négliger pour la réussite du projet.
Le reporting est la vitrine du décisionnel, les rapports mis à disposition doivent être impeccable en termes de design, compréhensible et simple d’utilisation. L’organisation et la mise à disposition des rapports doit être bien réfléchi en amont.
Comment bien restituer les indicateurs ?
Les modes de consommation du reporting ont évolué passant d’un reporting organisé par domaine fonctionnel à un reporting pour un profil utilisateur qui répond au besoin complet d’une fiche de poste. Au lieu de mettre à disposition de l’utilisateur des dizaines de rapports et de lui laisser faire le tri de ce qu’il lui est utile, on lui pousse la sélection des rapports dont il a besoin avec les filtres adaptés à sa fonction.
Par ailleurs, le reporting est organisé pour aller d’un point de vue macro vers du détail à la demande si cela est nécessaire pour interpréter un indicateur.
Il faut bien sûr se caler à l’organisation de l’entreprise mais classiquement les reporting sont déclinés d’une vision stratégique (type COMEX) à une vision opérationnelle.
Le macro permet de savoir si je suis en ligne avec les objectifs et le détail me permet de comprendre pourquoi je suis dans cette situation et en cas de non alignement avec les objectifs fixés, obtenir plus de détails.
On pousse la bonne information au bon moment à la bonne personne (reporting synthétique, alertes, …) puis on le guide pour comprendre et l’aider à prendre des décisions.
B- PENSER EN AMONT L’INDUSTRIALISATION DE VOTRE SYSTÈME D’INFORMATION
Maintenant que les briques du système sont bien comprises et avant de prendre le chemin entre votre situation actuelle et la destination cible, arrêtons-nous sur la phase d’industrialisation qu’il est nécessaire de penser dès le début de votre démarche au travers des quelques points d’attention et écueils qui suivent :
Production, Vente, Services, Marketing, RH, Comptabilité, Finance… afin de déterminer quel système est le référent maître de la donnée
Quand plusieurs systèmes traitent de la même donnée, lequel fait foi ?
Par exemple pour la donnée client qui peut être présente dans l’ERP et le CRM voire plusieurs CRM et plusieurs ERP … Dans ce cas il est nécessaire de mettre en place un référentiel.
Insee, Partenaires externes (marché, concurrence).
Par exemple identifier en amont des clients qui pourraient être sujets à des retards ou non-paiement, il est potentiellement nécessaire d’enrichir la donnée pour mieux connaitre l’entreprise puis de faire appel à des algorithmes d’IA pour identifier ces « mauvais payeurs ». Cela permet de passer d’une situation de constat à une démarche proactive.
Il faut éviter au maximum l’intervention manuelle :
- Ne pas utiliser de fichier en amont traité manuellement
- Mettre en place les automatismes nécessaires pour corriger la donnée : référentiel ou data cleansing
- Enrichir des données pour leur donner encore plus de valeur : normaliser (ex les adresses, mail ou tel) et compléter (enrichir la donnée manquante avec une source externe type Insee / Nomination)
est une étape importante qui ne se fait pas en une seule fois mais doit être un objectif fort et un élément clé du succès du projet. En effet, au-delà de l’aspect technique, il y a de réels bénéfices fonctionnels pour les utilisateurs :
- Rationalisation du reporting pour que tous les services partagent les mêmes indicateurs (définition, mode de calcul, compréhension : exemple du CA qui est le même en compta et pour les ventes)
- Même indicateurs quel que soit le niveau de la hiérarchie pour avoir un langage commun et permettre d’identifier la participation de chaque service à l’atteinte de l’objectif global.
- Des indicateurs mis à disposition très régulièrement (au moins tous les jours).
sont fonctionnels et présents quasiment à chaque projet :
- La qualité et la réconciliation de la donnée au niveau de l’entreprise et pas au niveau de chaque service ou entité.
- L’acculturation des collaborateurs aux enjeux de la donnée, de sa valeur, du partage nécessaire au sein de l’entreprise et la définition d’un langage commun par la mise en place au travers de la BI d’un point de vérité autour des « chiffres » de l’entreprise.
Maintenant que vous nous avez en tête le système décisionnel cible, voyons comment y parvenir en fonction de votre situation actuelle.
C- EN PARTANT D’UN EXISTANT
Vous avez bâti un système décisionnel depuis des années, cependant vous arrivez aux limites et vous n’arrivez plus à produire les indicateurs que le métier demande bien que les données soient disponibles.
Les systèmes décisionnels ont souvent été construits selon un schéma identique pour répondre à de nouveaux besoins sans avoir le temps de poser des bases solides, notamment quand la modélisation du DWH est similaire ou proche de celle des systèmes sources. Les outils de reporting ont aussi bien évolué et l’exploitation des données n’est à la main que de certains sachants, ce qui freine une utilisation et manipulation plus large du reporting.
Généralement, ce qui a été mis en place marche bien, mais il est difficile voir impossible de le faire réellement évoluer.
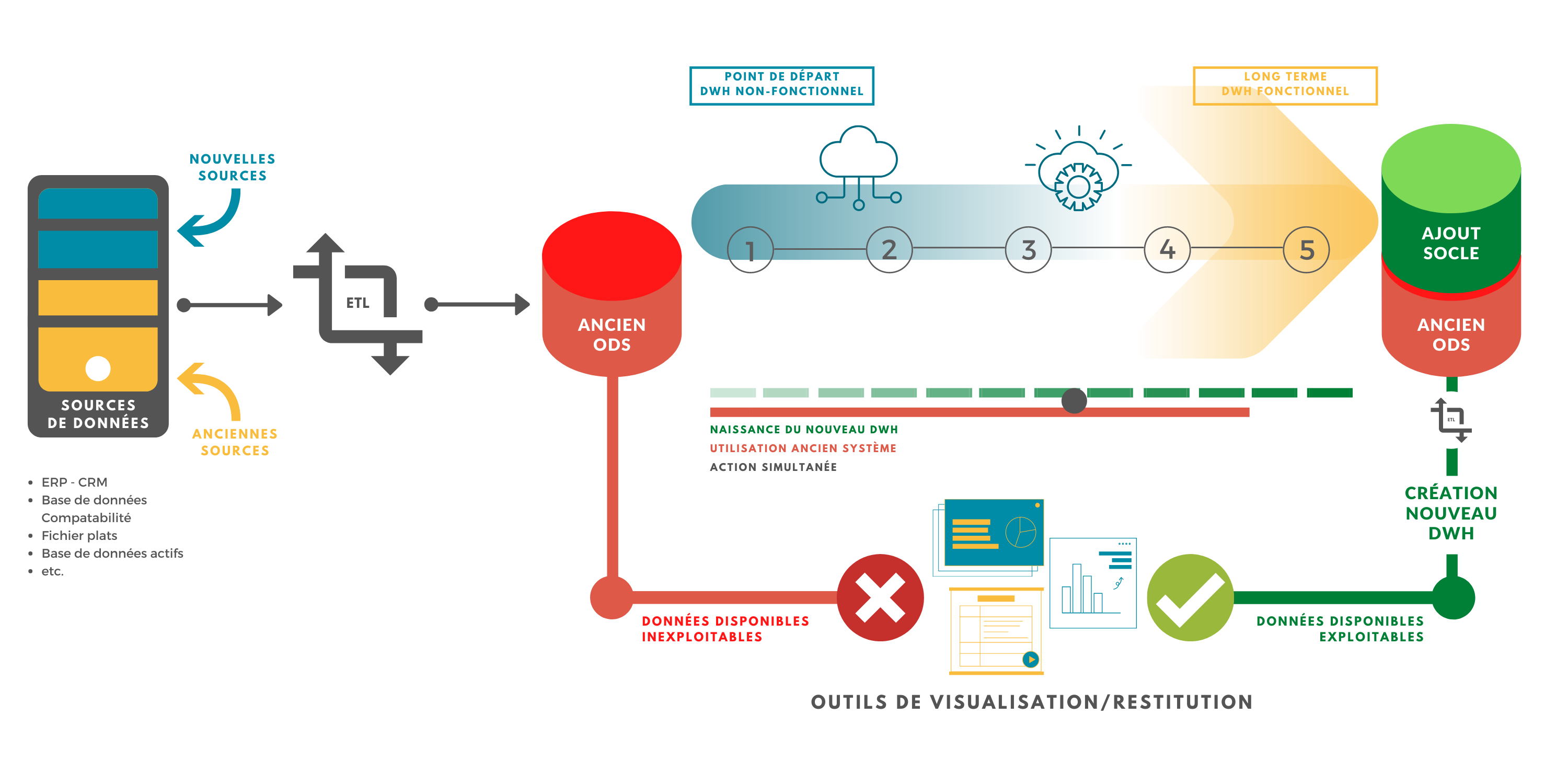
Afin de ne pas toucher à ce qui fonctionne, notre méthodologie est de construire en parallèle de la chaîne décisionnelle actuelle (Sources / DWH / Reporting) un nouveau DWH pour traiter le nouveau besoin. Le décommissionnement de l’ancienne chaine pourra se faire au fur et à mesure que les indicateurs et reporting concernés auront été pris en compte dans cette nouvelle chaine. L’idée ici est d’apporter en priorité de la valeur et ne surtout pas repartir de zéro tout en ne produisant aucun bénéfice notable pour les utilisateurs.
Cette démarche s’inscrit dans une perspective de long terme, le nouveau socle mis en place ayant pour objectif de remplacer à terme l’existant avec une structure pérenne et évolutive.
Méthodologie employée :
On garde la chaine décisionnelle existante mais on construit en parallèle un nouveau socle (DWH) pour répondre aux besoins d’aujourd’hui et aux enjeux de demain
On ne touche pas aux indicateurs existants, afin de ne pas mettre en danger le fonctionnement actuel de l’entreprise.
On répond aux nouveaux besoins avec une solution Cloud (ou On Premise fonction de l’intérêt de chaque client). Des fonctionnements hybrides sont tout à fait possibles.
On fait tourner les deux systèmes en parallèle sur des besoins qui sont disjoints.
On se décommissionne l’ancien DWH uniquement quand on décide de changer les systèmes sources ou plus en avance de phase lorsque les nouveaux besoins ont été mis en place.
Construction du nouveau Data Warehouse, selon la méthodologie Klint
D- EN PARTANT DE ZÉRO
Pourquoi mettre votre nouveau dispositif de Business Intelligence dans le Cloud ?
Vous n’avez pas encore de dispositif de BI au sein de votre entreprise, votre reporting est bâti sur des fichiers Excel. C’est une situation que l’on retrouve en fréquemment aujourd’hui et le Cloud est le bon moyen de vous montrer la valeur d’un véritable Système Décisionnel.
Le principal avantage du cloud est la scalabilité permettant de valider le nouveau système en ne traitant que le nouveau besoin (investissement ciblé) avant de le déployer à l’ensemble du système décisionnel puis de monter en charge en maintenant les performances du nouveau dispositif.
Cela va aussi permettre plus d’agilité par exemple en réalisant des expérimentations avec un coût d’investissement modéré et avec la capacité à revenir en arrière si ce n’est pas pertinent.
Le second avantage est de pouvoir bénéficier des fonctionnalités avancées du cloud (IA, Prédictif) là encore pour un budget accessible. Les éditeurs diffusent ces capacités dans l’ensemble de leurs solutions logicielles les rendant accessibles pour toute taille d’entreprise
Enfin un troisième avantage est de s’affranchir des contraintes d’infrastructures, de mise à jour pour les applications et une mise en place rapide de ces infrastructures sans passer par des investissements sur plusieurs années en serveurs et licences dès le début de projet.
Workflow Applicatif / Process d’intégration des données
CONCLUSION
Quelle que soit votre situation actuelle, vous devez faire de votre datawarehouse la pierre centrale de votre système décisionnel.
Et vous devez le faire dès maintenant afin que votre entreprise devienne réellement DATA DRIVEN. C’est la meilleure décision que vous avez à prendre pour être en mesure de piloter sereinement votre business.
Nos consultants sont à votre écoute et pourront mettre les valeurs qui sont les nôtres Expertise et Culture du Résultat au service de la réussite de votre projet.
La practice DATA/BI chez Klint
- 20 consultants certifiés sur les solutions Azure, AWS, Talend, Mulesoft, Power BI et Tableau Software.
- Compétences larges sur l’ensemble de la chaîne de transformation de la donnée : extraction, modélisation, stockage (construction DWH), reporting, visualisation, analyse statistique, cloud et on premise.



Fabrice
Fort de 20 ans de projets décisionnels réussis dans des secteurs d’activité variés, Fabrice conseille les DSI pour faire de leurs systèmes décisionnels l’atout performance de leurs entreprises.